1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| #!/usr/bin/env python3
import re #正则包
import requests #封装了 http 请求的包
from bs4 import BeautifulSoup #html 解析包
from datetime import datetime #时间包
#1. 将 wiki 上记录分享的网页下载下来,并进行解析
#注意点 1: 这里需要换成你自己想要解析的相应网页的 url(更换的网页地址之后记得重新定义网页的解析规则,即第 2、3、4 步的代码)
doc_url='你要解析的网页 url'
html_doc = requests.get(doc_url)
soup = BeautifulSoup(html_doc.content, 'html.parser')
#2. 利用正则找出所有的分享日期,并判断今日有无分享
date_list=soup.find_all(string=re.compile("分享日期"))
today = datetime.now().strftime("%Y-%m-%d")
#这里需要初始化一个不存在的分享日期,例如 1995-02-14
#todo 这里有一个 bug,就是如果同一天有多个分享,只会查出排在前面的那条记录。2018-03-11 21:16
next_share_date='1995-02-14'
for ele in date_list:
ele=ele[5:]
if ele==today:
next_share_date=ele
break
#3. 利用 BeautifulSoup 找出所有的分享内容
share_record=soup.find_all(string=re.compile("分享日期\s.*|分享时长\s.*|分享地点\s.*|分享简介\s.*|分享范围\s.*|分享人\s.*|《.*》"))
#4. 因为分享记录的格式固定,所以从分享日期开始往后的 7 个元素就包括了一次分享的所有记录
next_share_content=[]
for index in range(len(share_record)):
if next_share_date in share_record[index]:
for i in range(7):
next_share_content.append(share_record[index])
index+=1
else:
continue
#5. if 今日无分享,do nothing;else 通过钉钉的自定义机器人推送消息
if next_share_content == []:
print('next_share_content is null')
else:
print('next_share_content ',next_share_content)
date=''
time=''
place=''
title=''
summary=''
scope=''
author=''
href=''
for index in range(len(next_share_content)):
if '分享日期' in next_share_content[index]:
date=next_share_content[index]
if '分享时长' in next_share_content[index]:
time=next_share_content[index]
if '分享地点' in next_share_content[index]:
place=next_share_content[index]
if '《' in next_share_content[index]:
title=next_share_content[index]
#将 '分享主题' 四个字替换成 '' 空串,这样就能去除重复的 '分享主题'四个字。
p = re.compile('分享主题')
title=p.sub('',title)
#取出分享主题的链接
href_list=soup.find_all('a')
for i in range(len(href_list)):
if title in href_list[i]:
href=href_list[i].get('href')
break
if '分享简介' in next_share_content[index]:
summary=next_share_content[index]
if '分享范围' in next_share_content[index]:
scope=next_share_content[index]
if '分享人' in next_share_content[index]:
author=next_share_content[index]
#如果分享主题没有链接,则正常发主题;否则,把链接也加上。
if href=='':
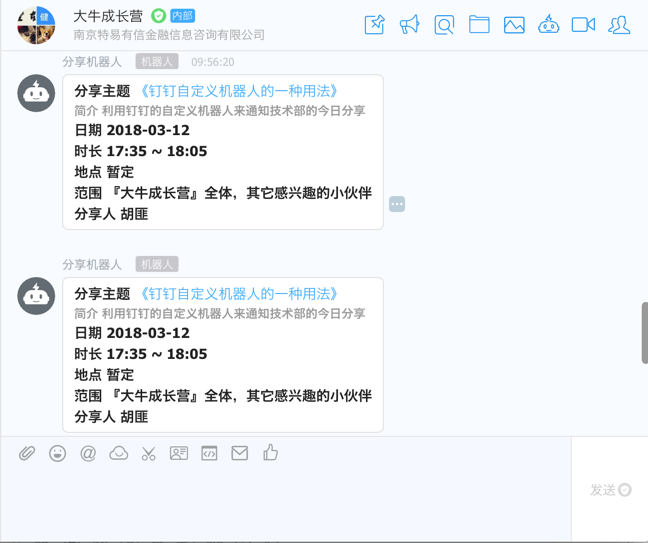
str_list=['{"msgtype":"markdown","markdown":{"title":"今日分享","text":"### **分享主题** **',title,'** \n','###### **',summary[2:],'** \n','##### **',date[2:],'** \n','##### **',time[2:],'** \n','##### **',place[2:],'** \n','##### **',scope[2:],'** \n','##### ',author,' "','}',',"at":{"atMobiles":[],"isAtAll":true}','}']
else:
str_list=['{"msgtype":"markdown","markdown":{"title":"今日分享","text":"### **分享主题** [',title,'](',href,')', '\n','###### **',summary[2:],'** \n','##### **',date[2:],'** \n','##### **',time[2:],'** \n','##### **',place[2:],'** \n','##### **',scope[2:],'** \n','##### ',author,' "','}',',"at":{"atMobiles":[],"isAtAll":true}','}']
message=''.join(str_list)
print('message', message)
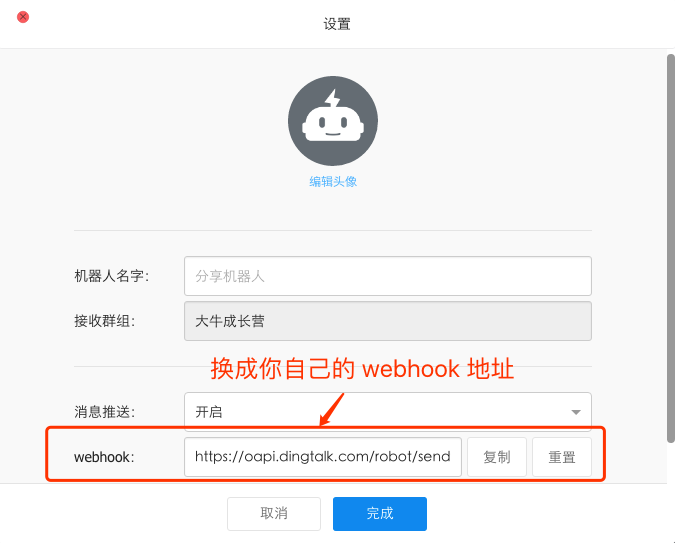
#注意点 2:dingding_url 需要替换成你自己钉钉机器人的 webhook 地址
dingding_url='webhook 地址'
headers={"Content-Type": "application/json"}
r = requests.post(dingding_url, data=message.encode('utf-8'), headers=headers)
|